I joined Shopify in 2021.
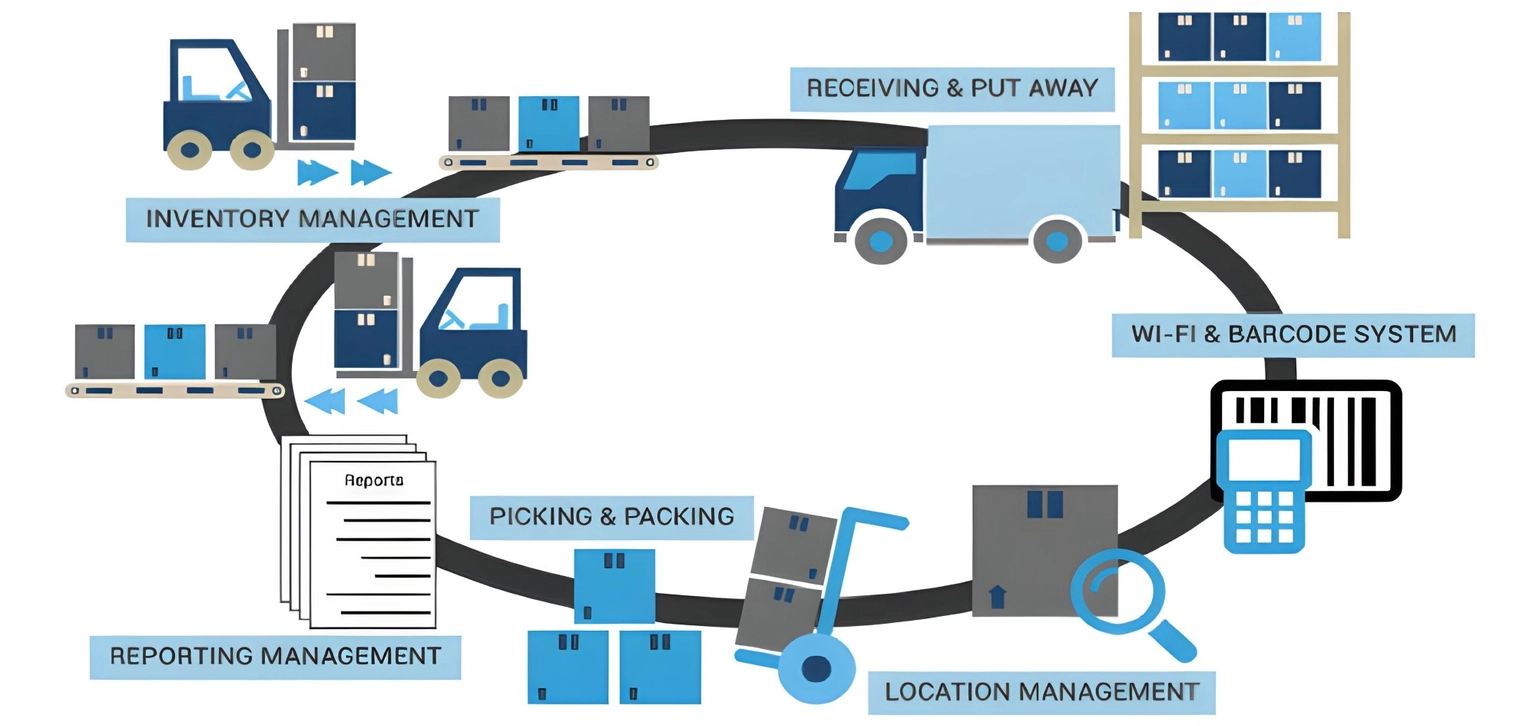
At Shopify, my team was responsible for the code that powered the receiving workflow in our warehouse management system (WMS).
A diagram of a typical WMS (credit: Wikipedia)
Receiving refers to accepting inventory into the warehouse. The items need to be unloaded, inspected, and moved to a staging area for putaway. Because receiving is a critical part of the inventory lifecycle, a lot of our work was in support of other teams.
Our software had 2 types of users: warehouse associates and robots. The robots were like a cross between a Roomba® and a shopping cart. Because algorithms are really good at pathfinding, the robots were able to guide the associate along the most efficient path possible through the warehouse. When the associate scanned an item with a barcode scanner, the robot would know if the associate scanned the wrong item or didn’t scan enough items.
My job was to figure out how to make the pieces of the puzzle fit.
For example, imagine a warehouse associate is receiving 50 items. As they are scanning them into the system, they discover 3 are damaged. 1 is not fit for sale; but 2 are just missing price tags that can be re-attached.
When developing a solution, there are technical as well as physical considerations that have to be made. How do you implement that in a way that doesn’t break the system and doesn’t require other teams to completely rewrite their services? You can’t prompt the associate to “walk over there” because there might be a 10 minute walk. Finally, different warehouses have different capabilities, so each deployment needed to be configurable by the site.
Like a lot of tech companies in 2023, Shopify made some organizational changes. You can read more in the official announcement, but the gist is there was a 20% headcount reduction, including my entire team.
Funemployment
At this point (early summer ‘23) I was using GitHub Copilot and ChatGPT daily and was interested not only in how they worked, but also how I could incorporate ML (machine learning) and generative AI into actual products. Pretty much since ChatGPT was launched I had been thinking about AI non-stop. I was playing around with the OpenAI API, made a Fish client, and started to explore the OpenAI Cookbook.
The cookbook is a collection of Jupyter notebooks. If you aren’t familiar with Jupyter, it’s a web-based interactive notebook where you can mix prose with code. Code is run in kernels (runtimes) and the default kernel is Python. It’s widely used in data science and machine learning.
I had an idea to use the tslab kernel to experiment with the ChatGPT client for Node as well as other ML libraries in the JS ecosystem like TensorFlow.js and Transformers.js.
I created the jupyter repo as a way to experiment with it. Long story short, I got hooked on Python and decided to learn as much as I could about ML and deep learning.
Learning
When it comes to learning new web frameworks or tools, I usually just npm install and work my way through the docs. For a new API, I open Hoppscotch and start firing requests.
For ML, I took a more structured approach.
DataCamp
I started with DataCamp. The curriculum is divided into tracks which are like playlists of courses. The courses are all done in the browser using DataCamp’s custom Jupyter-like environment.
I found it very easy to follow along locally, so I created the datacamp repo which contains all of my notebooks along with their datasets. You can read my notes on supervised and unsupervised learning, or you can to run my code for the linear classifiers course.
Over the remainder of the summer and fall, I completed the following tracks:
- Python: Datetimes, RegEx, OOP, DSA,
pytest. - Data Engineering: Building data pipelines into DataFrames.
- Data Science: NumPy, SciPy, Matplotlib, Seaborn, Statsmodels, Scikit-learn, etc.
By the time I got to the machine learning track, I wanted to switch things up a bit.
Fast.ai
The DataCamp ML track doesn’t get to neural nets (deep learning) until the end. For some perspective, I had spent months learning EDA, feature engineering, data visualization, and statistics. It was time.
The Fast.ai course is one of the most popular deep learning courses. It’s centered around PyTorch and the fastai library.
The course consists of video lectures and exercises. There’s also a Kindle version, which I ended up purchasing. It’s been a great read as it covers a lot of history, real-world applications, and ethics with regards to deep learning. Once finished, I plan on working through the Fast.ai computational linear algebra course.
I opted towards reading the book rather than work through the coursework. As an aside, I was pretty impressed I was even able to read this book because that meant my data science literacy and vocabulary had improved. I now have hundreds of dollars in more O’Reilly books on my wish list.
I came across this course while looking for TensorFlow resources. It starts with an introductory video from Peter Norvig followed by the Rules of ML, a 3-phase approach to deploying models in production based on actual experiences at Google.
What I really like about it is that it’s presented as mostly text with illustrations and diagrams. The information is condensed very nicely, which makes it a great reference to revisit in the future. There’s also an accompanying glossary.
I also worked through the practice notebooks for CNNs for image classification and GANs for image generation using TF-GAN for TensorFlow.
Learning about GANs was very interesting. If you’re unfamiliar, check out Phil Wang’s thispersondoesnotexist.com. The images are generated by StyleGAN2 from NVIDIA Research, which is a TensorFlow implementation of the paper (Karras et al., 2020).
A GAN is actually 2 models: a generator that tries to create real-looking images, and a discriminator that attempts to classify images as real or fake. This is why they are called adversarial networks. As the discriminator gets more accurate, the generator produces better images. When training is complete, the discriminator is discarded and the generator can be deployed to generate new images.
HuggingFace
Once I was comfortable with neural networks, I wanted to complete one of the HuggingFace courses.
HuggingFace (🤗) is sort of like the GitHub of pre-trained models and datasets. Their open source team is responsible for popular libraries like transformers and diffusers for Python and candle for Rust. Their NLP (natural language processing) course is lead by Sylvain Gugger, who co-authored the Fast.ai book.
This was a deep-dive into the transformers and datasets libraries while concurrently teaching a lot of NLP concepts like text generation, summarization, and translation. It was also the most in-depth course I found specifically on the Transformer architecture, which is the technology behind ChatGPT.
The course ends with a light introduction to Gradio and Spaces, which allow you to not only deploy your models with an inferencing endpoint, but also create a nice looking UI for them. Check out the sketch-recognition demo for an example.
Next
A lot of this:
def two_sum(nums, target):
num_dict = {}
for i, num in enumerate(nums):
if target - num in num_dict:
return [num_dict[target - num], i]
num_dict[num] = i
return []Website
Digital gardening is something that has intrigued me for a while and is the primary motivation for making this site more than just a landing page.
I do want to build out the site more, beyond just the blog and about pages. A now page is next up. I also was thinking about a personal /readme page, inspired by jongleberry.com/manager-readme.
I have looked at a few ways to add interactive coding to the blog like JupyterLite, DataCamp Light, and Sandpack. They are all trivial to add, but there are performance and a11y considerations I need to look into first. Also, I need to do it in a way that is useful.
Coding
I never made it to a formal PyTorch course (Fast.ai doesn’t count) because I wanted to stick with TensorFlow. For learning some lower-level concepts like automatic differentiation, I used JAX. When I get back into ML, I defintely want to get better at JAX as well as Flax.
At DataCamp, I still want to finish the ML track, as well as the the NLP and Time Series tracks.
Back in web land, I would like to build something with CRDTs and continue exploring worker runtimes.
Writing
Most of my GitHub repos and gists are tutorials, templates, or tools. My most starred things are guides on MongoDB in Docker and SSH for Windows.
This is all great content for the site, so I need to do more of it. That said, it needs to be organic; I don’t want my pristine digital garden to be littered with Medium.com-esque captain-obvious posts.
Reading
Next up is The Shape of a Life.
The biggest rabbit hole is trying to answer the question where did the universe come from?
In an attempt to answer this question, many people have been trying to prove string theory. There are a few types, but they all require extra dimensions beyond the 3 spatial and 1 temporal that we experience. In order to make these theories make sense, the extra dimensions need to be folded in a special shape. One such shape is the Calabi-Yau manifold, named after mathematicians Eugenio Calabi and Shing-Tung Yau.
This book is about Yau’s life. It sounds like he came from humble beginnings yet was able to win the Fields Medal (no relation) by his early 30’s. I’m very curious to read about his experience.
School
When researching ML courses, I came across CU Boulder’s MS in Computer Science. This is actually the same degree they give on-campus, but broken into 30 credits instead of 10 (3 courses online is equivalent to 1 course on-campus). To be admitted, you have to audit 3 courses and get a B or better.
This is definitely a H2 ‘24 goal if I even get to it. I’ll need to find my stride at work first before I can commit.
Conclusion

Turtle Bay, Oahu on December 7 (credit: me)
2023 was a solid year. Lots of learning with some leisure and plenty to look forward to. I hope you have a happy New Year and that you’ll follow me on GitHub and Hugging Face 🥂.